Ask in plain English. Build the workflow as you talk. No-Code. No Hassle.
Describe what you need. Your AI Data Analyst and AI Data Engineer turn plain English into a trusted, repeatable workflow — grounded in the Semantic Layer powered by SemantIQ. Your data never moves. Save the output as a Virtual Live Dataset or share it as a DaaS API — a reusable asset, not a dead screenshot.
Built for analysts, stewards, business users, and data scientists who've had enough of waiting on data engineering. Athyna turns a data request into a data product — before your coffee gets cold.
Analysts spend most of their day wrangling files, chasing nulls, joining sheets, and writing one-off SQL that nobody reuses. The work is slow, repetitive, and it stays trapped in notebooks and Slack DMs. By the time the answer is ready, the question has changed.
Athyna compresses that entire cycle. Pair with the AI Data Analyst or AI Data Engineer, describe the prep in English or drag-and-drop a visual workflow, and Athyna compiles it, runs it on an in-memory SQL engine, and saves the result as a governed, reusable data product. The Semantic Layer — powered by SemantIQ — keeps every transform grounded in the same business definitions your BI, governance, and ML pipelines already use. The work compounds instead of disappearing.
Data prep isn't a chore. It's a product in the making.
Athyna is where two members of the xAQUA AI Data Team do their work — the AI Data Analyst and the AI Data Engineer. Both speak plain English. Both work against the same Semantic Layer. Both leave behind a versioned, reusable workflow.

Connect anywhere. Build a workflow. Transform with AI. Validate. Publish as a live data product. All from one codeless canvas — with your data staying where it is.
From Excel to Snowflake — with twelve built-in tasks a few clicks away. Profile, schema, and visualization update live as you build.
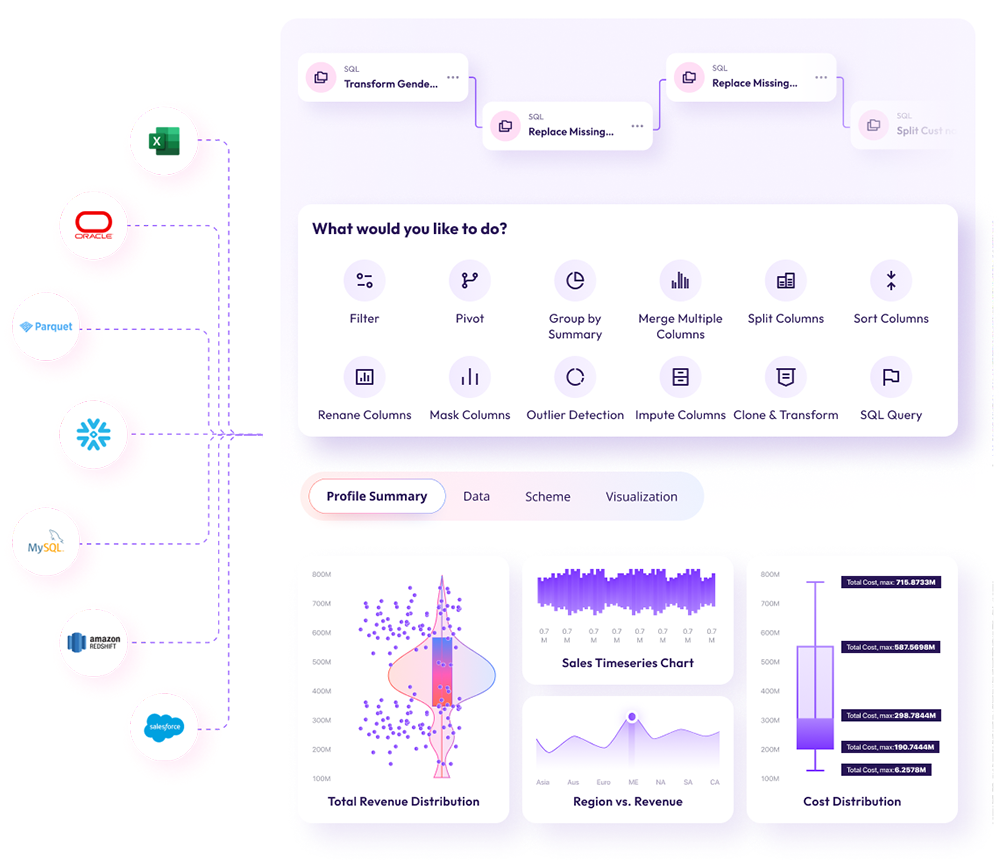
Connect any source — Snowflake, Databricks, Oracle, Redshift, MySQL, Salesforce, S3, Excel — and chain together a workflow from a full library of tasks. Profile, Data, Schema, and Visualization tabs update at every step.
A point-and-click toolkit covering the work that fills 80% of an analyst's day. Each task is a versioned, reusable step in your workflow.
Five steps from raw data to actionable insight — with governance built in and your data never leaving your boundary.
You describe the prep the way a colleague would describe it — "Mask SSN," "Create Customer Age Group," "Calculate the corrected age & income" — and the AI Data Analyst grounds the request against the Semantic Layer, generates SQL, runs it in memory, and shows you the result with full lineage and profile.
Every prompt becomes a task in your workflow. Chain them. Branch them. Reuse them. The whole sequence becomes a Virtual Live Dataset — so the next analyst doesn't have to start from scratch.
# Described by analyst · compiled by Athyna ask "merge 3 member files, dedupe on member_id, coalesce SSN from first non-null, flag rows where DOB > today" ── compiled SQL ── WITH unified AS ( SELECT * FROM members_q1 UNION ALL SELECT * FROM members_q2 UNION ALL SELECT * FROM members_q3 ), deduped AS ( SELECT member_id, COALESCE(ssn_a, ssn_b, ssn_c) AS ssn, dob, ROW_NUMBER() OVER (PARTITION BY member_id) AS rn FROM unified ) SELECT *, (dob > CURRENT_DATE) AS invalid_dob FROM deduped WHERE rn = 1; ── execution ── scanned 8,213,044 rows duration 340ms ✓ PASS output 7,913,812 clean rows flagged 14 invalid DOBs STATUS: READY · save as Virtual Live Dataset?
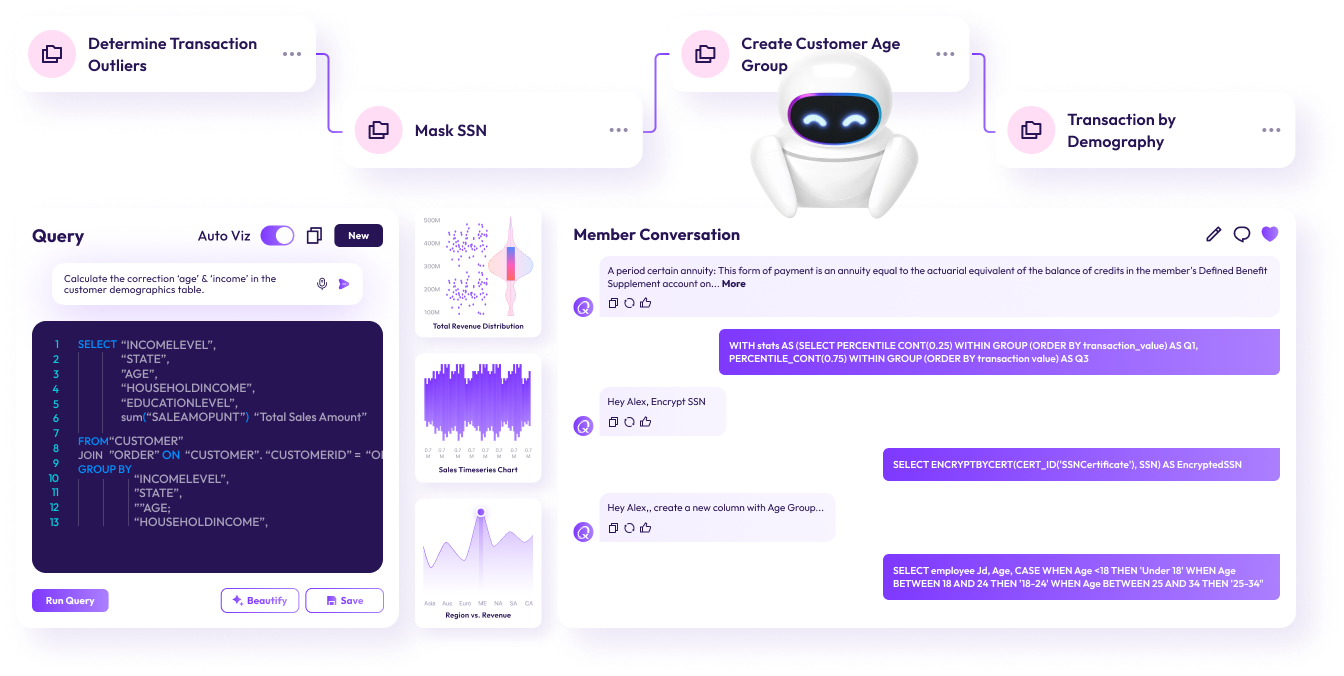
Workflow tasks — Determine Transaction Outliers · Mask SSN · Create Customer Age Group · Transaction by Demography — chained into a reusable workflow. Ask in English; the AI Data Analyst writes the SQL; Cezu narrates what happened.
A clean dataset shouldn't die in a notebook. Athyna gives every workflow two lives — discoverable in the catalog and consumable as an API.
Athyna is a module of a unified platform — not a standalone prep tool bolted onto someone else's catalog.
Athyna is the interactive studio. Composer — xAQUA's pipeline builder — picks up where you stop. Promote any Athyna workflow to a scheduled, governed, CI/CD'd Airflow DAG with a single click.
Ask the AI Data Engineer in plain English: "Promote yesterday's member prep into a daily pipeline" — it wraps the workflow, adds quality gates, versions it in Git, and deploys to production.
Meet the AI Data Engineer →main/pipelines/members_dailySee Athyna profile a live dataset, run a natural-language transform, and publish the result as a governed data product — in under fifteen minutes.
Or email us directly at sales@xaqua.io