Summary: After a year building agentic analytics for healthcare systems, government agencies, and pension funds, I learned something the industry doesn’t talk about: enterprise AI is 20% artificial intelligence and 80% data engineering. The AI was the easy part. The hard part? 500 tables, 20,000 cryptic columns, and tribal knowledge locked in the heads of DBAs who retired years ago.
Everyone’s chasing better LLMs, bigger context windows, and autonomous agents. Wrong problem. The future of conversational analytics isn’t agents that discover your data—it’s agents that already understand it, because you built a semantic layer that engineered them that way. Start with semantics, retrieval, and governance. Not the model. That’s where success or failure is decided.
This article shares six lessons on building enterprise-scale AI analytics that actually work in production.
I started 2025 believing the hype.
I thought AI agents could simply talk to your data – you ask a question in plain English, and it gives you insights instantly. The demos were amazing, showing an AI answering questions like “What were our top products?” in seconds. But those demos used perfectly clean data with obvious names like products and sales.
I ended 2025 with a very different view.
After spending a year building these systems for enterprise clients – healthcare providers, government agencies, public pension funds, and financial institutions running decades-old systems with messy databases and thousands of confusing columns – I realized something the conferences don’t tell you:
This is an engineering problem, not just an AI problem.
Here are the six lessons that changed how I see this technology.
Early on, our team struggled with a simple request: “Show me diabetic patient readmissions by primary care provider.”
The AI was smart, but it didn’t know the specific language of this company’s database. It didn’t know that:
We tried forcing the AI to figure it out by changing the prompts, but it didn’t work. Things only started working when we built a “semantic layer” – basically a detailed dictionary that mapped business terms to those cryptic database column names.
The Takeaway: No amount of smart AI can make up for undefined data. You need a rich dictionary (metadata) as your foundation.
There is a popular idea called OSI (Open Semantic Interface) that suggests you can just write down all your data definitions in simple text files (YAML files), and the AI will understand them.
That sounds nice, but in reality, big companies have:
Who is going to write and update 20,000 definitions? For old companies, simply creating this understanding is the hardest part.
Furthermore, AI needs more than just a description. Here’s what a simple YAML-based approach provides versus what enterprise AI actually needs:
The Solution: You can’t document 20,000 columns by hand.
We built an auto-discovery pipeline instead – engineering first, AI second.
The engineering layer extracts schema, relationships, sample data, categorical values, metrics, and data quality scores across all data sources automatically.
The AI layer enriches descriptions using business context, auto-maps columns to glossary terms, and assigns confidence scores to each mapping.
High confidence → auto-publish.
Low confidence → flag for human review.
The result: a living, governed catalog – not a static YAML file that’s wrong by Tuesday.
The Takeaway: Manual documentation doesn’t scale. Auto-discovery with human-in-the-loop governance does. And the catalog must encode tribal knowledge – the unwritten rules that separate “technically correct” from “actually useful.”
Everyone spent 2025 celebrating “autonomous” agents – AI that figures out its own path.
We tried that. When we let an agent search 300 tables on its own, it got overwhelmed. It found too many columns, the amount of information exploded, and it started hallucinating (making up connections that didn’t exist).
The breakthrough happened when we stopped letting the AI wander and started giving it a map. Here’s the difference:
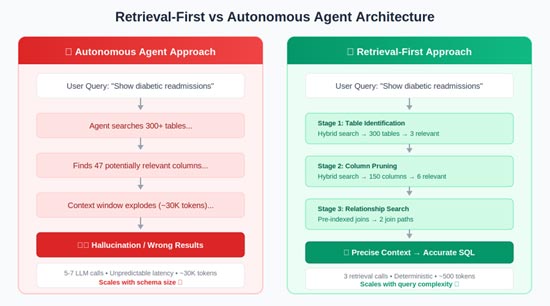
We built a system that:
The Takeaway: Autonomy is a band-aid for not knowing your data. If you give the AI precise context upfront, it works much better. Informed planning beats brute-force exploration.
People kept telling us, “Just wait for smarter AI models with bigger memories.”
But the math doesn’t work out:
Key Result: We reduced context from ~30,000 tokens to ~500 tokens – a 60x reduction. This meant deterministic retrieval instead of AI hallucination risk, and analysts started trusting answers because they could see the plan, SQL, and reasoning.
The Takeaway: The winners aren’t the ones with the smartest models; they are the ones with the best search (retrieval) systems.
In controlled enterprises such as healthcare, finance and government, you can’t just trust a black box. When an AI answers a question about patient data, someone needs to verify it.
We learned to make the AI transparent. We made it show:
People used the tool more – not because the answers were better, but because they could verify them.
The Takeaway: In enterprise contexts, explainability isn’t a nice-to-have. It’s what separates a demo from a deployment.
When we looked back at our biggest headaches, they all traced back to the data catalog (the “dictionary”):
Fixing this isn’t “AI work.” It’s engineering work – data engineering, metadata engineering, retrieval engineering.
If you are building this kind of system next year, here is what you should do:
The industry still loves the idea of magical, autonomous agents. I get it – it makes for great demos.
But working with messy, real-world data taught me that the future isn’t about agents that discover your data. It’s about agents that already understand it – because you engineered them that way.
The future belongs to organizations who treat AI as the final mile – and invest first in semantics, retrieval, governance, and engineering discipline. That’s how you get accuracy, trust, cost-control, and real adoption—not just great demos.
Here’s to building that foundation in 2026.
What were your biggest lessons building with AI in 2025? I’d love to hear what surprised you.
If you’re planning AI initiatives for 2026, start with semantics, retrieval, and governance – not the model. That’s where success or failure is decided.
Sanjib Nayak is Founder and CEO of xAQUA (say Zaqua | xaqua.io), building a Conversational Data Management platform where technical and business users collaborate with an AI Data Team – AI Data Analysts, AI Data Engineers, AI Data Scientists, AI BI Specialists, AI Data Governance, and AI Data Stewards – using natural language, no code required. An industry veteran with 30+ years serving government agencies and Fortune 500 enterprises, Sanjib believes 80% of users can’t do their own analytics – not because they’re not smart, but because the tools are too complex. He’s a believer in Smart Data over Big Data: simple, smart systems that serve 98% of use cases at enterprise scale, not complex, expensive solutions over-engineered for the 2%.