Our Data Pipeline Automation as a Service (DPAaaS) is powered by an integrated Metadata Knowledge Graph, Data Catalog Embedding, Data Quality Management, and Augmented Intelligence. xAQUA® UDP is designed to increase productivity throughout the end-to-end Data Operations lifecycle.

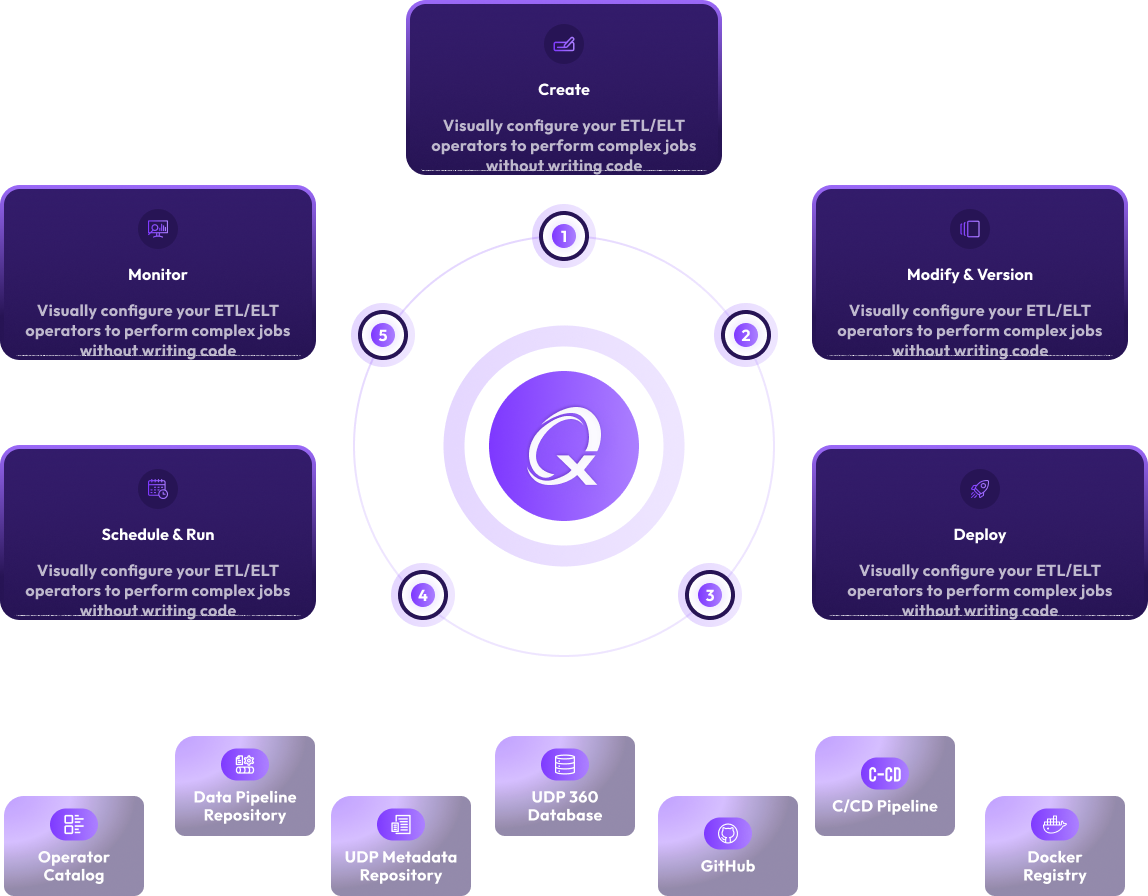
Keep the time, cost and risk of your data integration projects under control. Using xAQUA® Compose, Deploy, Run, Test, Manage, and Monitor your data process lifecycle at scale – rapidly and efficiently. Do-it-yourself (DIY) using xAQUA® Composer – end to end data operations lifecycle tasks using self-service low code/no-code user interface-driven tools with automated deployment and CI/CD pipelines.

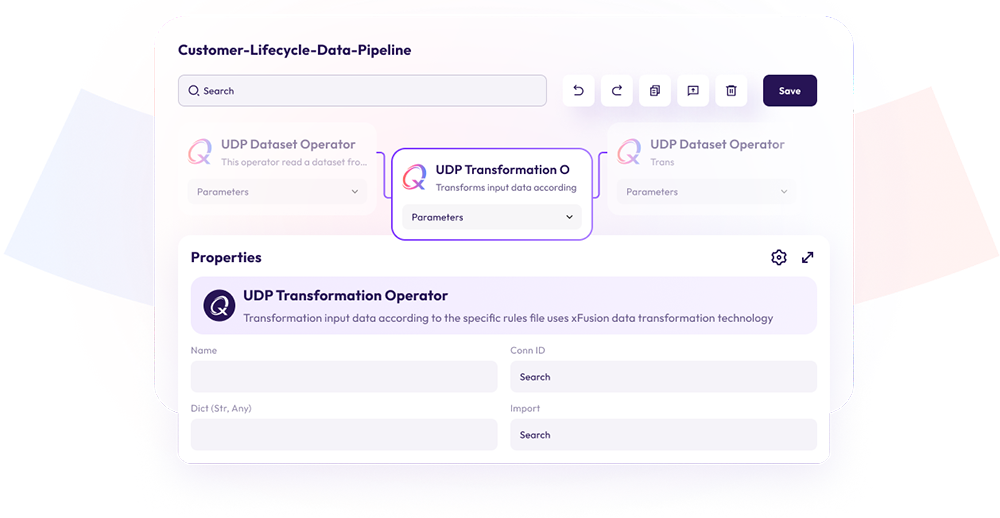
Low Code/No Code Drag and Drop Composition of Apache Airflow DAGS
Visually configure your ETL/ELT operators to perform complex jobs without writing code
You can Drag and Drop all operators including Airflow, Providers, and Custom Operators from the Operator Registry.
Compose and deploy your first data pipe line on Apache Airflow on Day 1
Compose and deploy your first data pipeline on Apache Airflow on Day 1
Low Code/No-Code Drag and Drop Composition of Apache Airflow DAGS
Visually configure your ETL/ELT operators to perform complex jobs without writing code
You can Drag and Drop all operators including Airflow, Providers, and Custom Operators from the Operator Registry.
Compose and deploy your first data pipeline on Apache Airflow on Day 1
Detect the schema change impact automatically in design-time and run-time.
View data profile, enforce and ensure data quality in every step of data pipeline.
Our out-of-the box ETL solution automatically infers schema during design time and runtime and ensures the data integrity of your target database.
Ensure Quality of your Patient or Customer data while bringing data to the MDM Repository or target data stores/Data warehouses using our Probabilistic Entity Resolution UDF for Apache Spark.
Know in minutes why your data pipeline broken, see the historic performance of pipelines, SLAs, detect anomalies and send alerts.
Detect the schema change impact automatically in design-time and run-time.
View data profile, enforce, and ensure data quality in every step of data pipeline.
Our out-of-the box ETL solution automatically infers schema during design time and runtime and ensures the data integrity of your target database.
Ensure Quality of your Patient or Customer data while bringing data to the MDM Repository or target data stores/Data warehouses using our Probabilistic Entity Resolution UDF for Apache Spark.
Know in minutes why your data pipeline is broken, see the historic performance of pipelines, SLAs, detect anomalies and send alerts.
Deploy Host, Apache Airflow and Spark Clusters on Kubernetes with few clicks.
Manage DAG Versions DAG automatically with an integrated GitHub repository
Deploy DAGS on your environments with few clicks with our integrated and automated CI/CD pipelines.
Text not available
Text not available
Your ML Model is as good as your data. The quality and amount of data used to train your model directly define the performance of your ML Model. Acquiring and preparing clean and quality data for the specific ML Model use case is very intensive and highly time-consuming job.
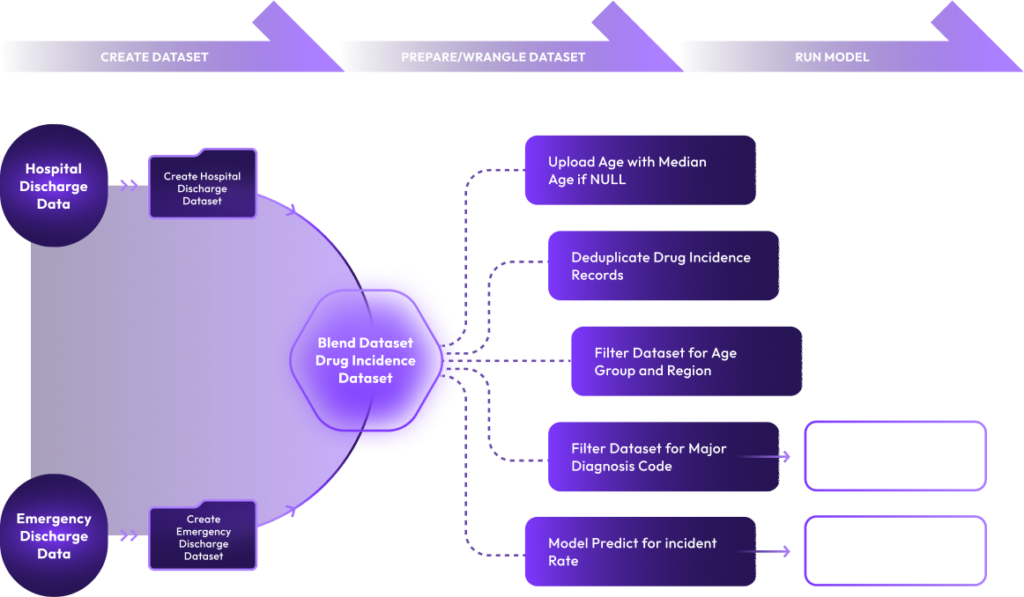
xAQUA Composer provides low code/no code drag and drop user interface to create, configure, deploy and run pipelines to acquire and prepare datasets that can be used to train and test ML Models in minutes.
xAQUA Composer provides highly interactive user experience to configure and perform Data Ingestion, Transformation, Exploration, Profiling, Validation, Wrangling/Cleansing, Blending and Splitting Datasets without writing any code.
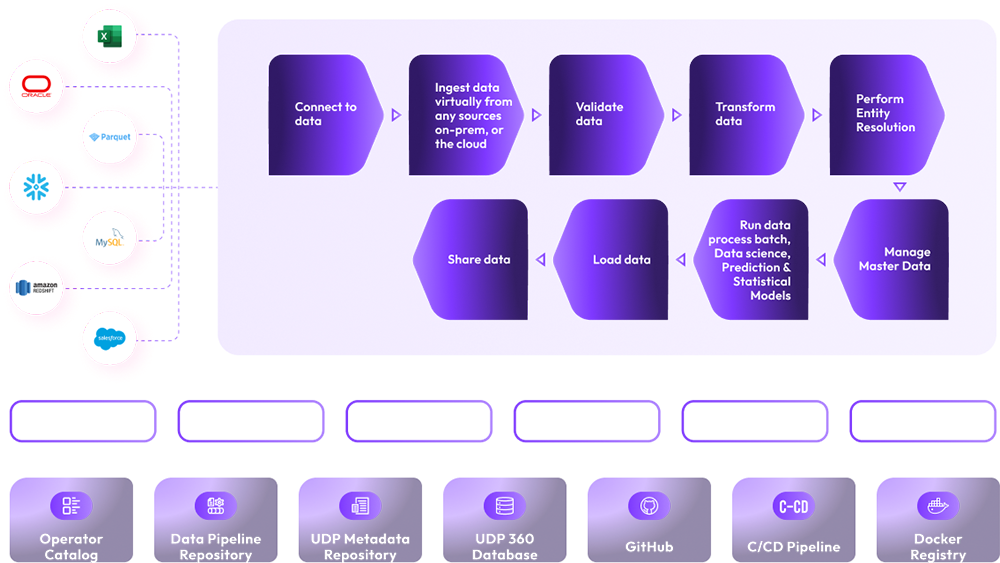
Keep the time, cost, and risk for your data integration projects under your control using xAQUA® Composer. Compose, Deploy, Run, Test, Manage, and Monitor your data process lifecycle at scale – rapidly and efficiently. Do-it-yourself (DIY) using xAQUA® Composer – end to end ELT data pipeline lifecycle tasks using self-service low code/no-code user interface-driven tools with automated deployment and CI/CD pipelines.
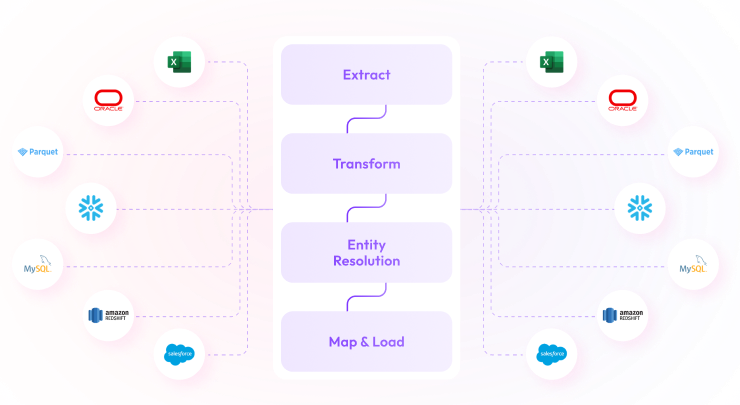
xAQUA® Composer provides out of the box connectors and operators to extract data in real-time, batch and streaming mode virtually from any data sources.
Ingest the extracted data as-is using out-of-the box data ingestion operator to the UDP Data Lake.
Out-of-the-box operators allow you to perform virtually any type of data transformation using low-code/no-code configuration-driven operators.
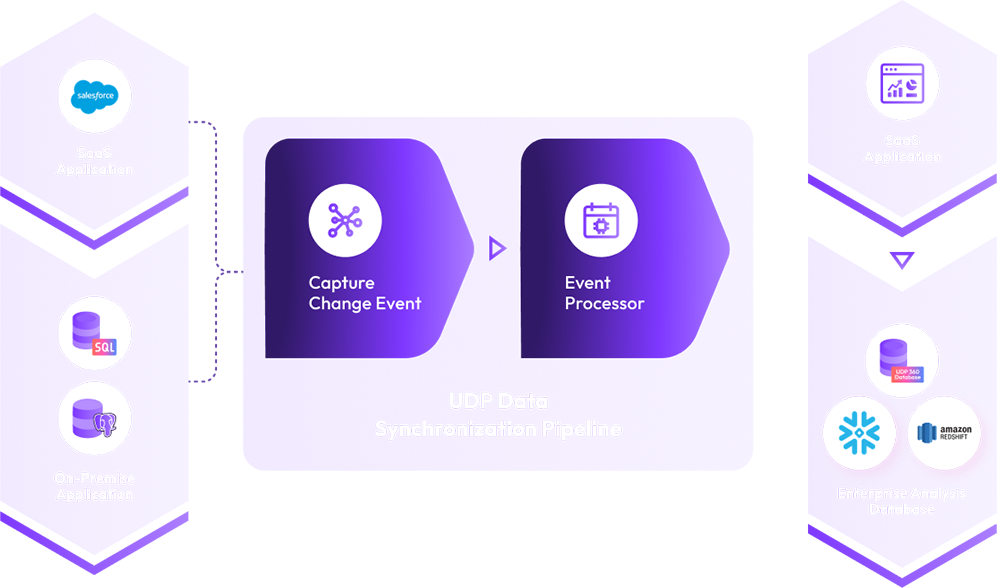
You may have siloed operational systems across the enterprise, few are on-premises, few are on the cloud and few are delivered as SaaS. The enterprise lacks a single integrated view of the data that can be used to create trustworthy actionable insights. An Enterprise Analytics Database can be a solution that will maintain an integrated 360 view of the operational data across the enterprise.
xAQUA UDP uses a Graph Database platform to establish a 360-degree connected view of the data. This allows the power of connected data and data science to rapidly deliver actionable insight.
Change Data Capture (CDC) from multiple operational systems is the key capability for the Enterprise Analytics Database solution. Capture Change Data using our Apache Kafka Stream interface in real-time or near real-time using API pooling from external systems including Databases on-premises, on the cloud and SaaS platforms such as Salesforce and apply the changes to another database. You can create a centralized Enterprise Analytics Database by capturing data from various operational systems and applying the updates from the transactions in the operational systems in real-time or near real-time. The Enterprise Analytics Database shall have integrated 360 view of integrated operation data that can be used to perform analytics enterprise wide and share the data to external partners.
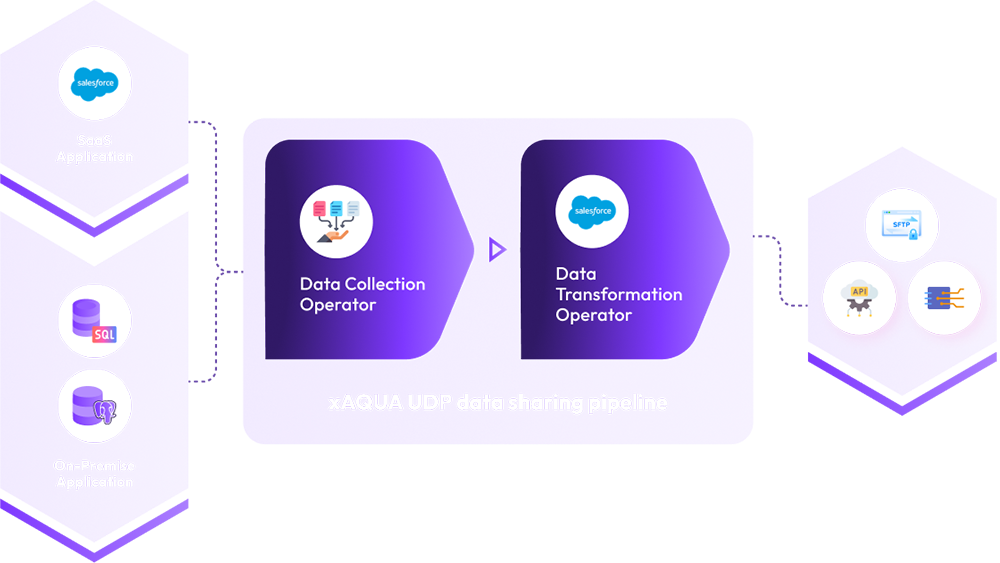
Integrate data from multiple operational systems into one enterprise analytics database in batch, real-time and near-real time mode.
Establish Cloud Data Gateway – bring data from multiple operational systems on SaaS platforms (e.g. Salesforce, ServiceNow etc.).
Share data with partner systems – API Gateway and Data as a Service (DaaS)
Deliver the integrated to another on-prem or cloud data warehouse such as AWS Redshift, and Snowflake.
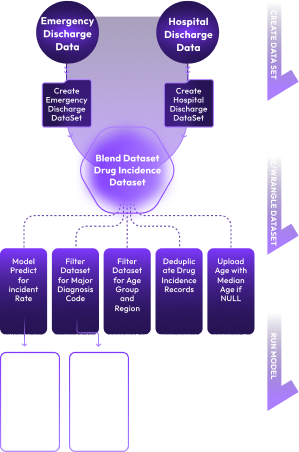
Your ML Model is as good as your data. The quality and amount of data used to train your model directly define the performance of your ML Model. Acquiring and preparing clean and quality data for the specific ML Model use case is very intensive and highly time-consuming job.
xAQUA Composer provides low-code/no-code drag and drop user interface to create, configure, deploy and run pipelines to acquire and prepare datasets that can be used to train and test ML Models in minutes.
xAQUA Composer provides highly interactive user experience to configure and perform Data Ingestion, Transformation, Exploration, Profiling, Validation, Wrangling/Cleansing, Blending and Splitting Datasets without writing any code.
With xAQUA Composer, you can create, deploy and run a Machine Learning Data Pipeline Model Training, Model Evaluation, Model Testing, and Model Packaging in minutes using the low-code/no-code drag and drop user interface.

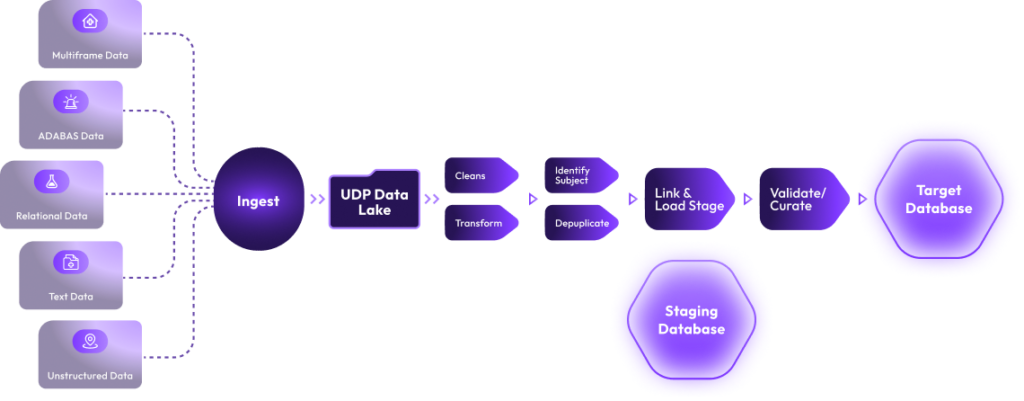
Subject (Person, Population, Product, Organization) Centric approach.
Integrate data from multiple external and internal systems in batch, real-time and near real-time mode.
Create 360-degree view of connected master data, longitudinal temporal events, location and spatial data
Establish Master Subject Index (MSI) e.g., Master Member Index and Master Patient Index,
Perform Interactive visual analysis of master data, and events.
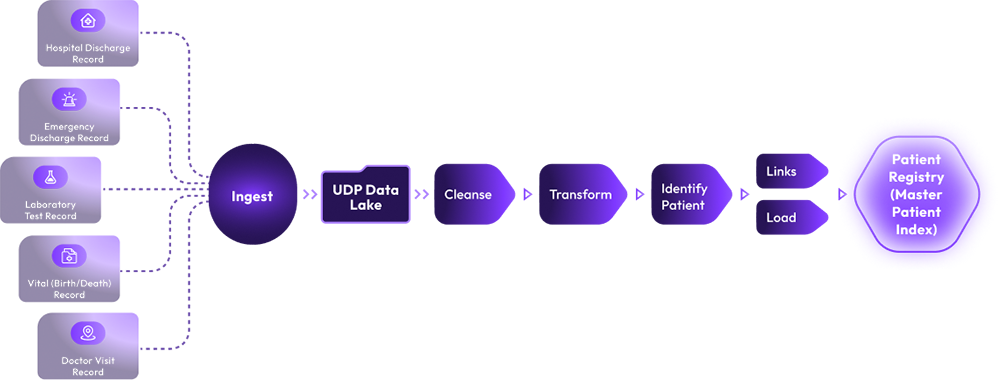
Extract, cleanse, transform, and integrate data from multiple legacy operational systems.
Increase data quality and trust.
Deliver clean and integrated data to the modernized system.
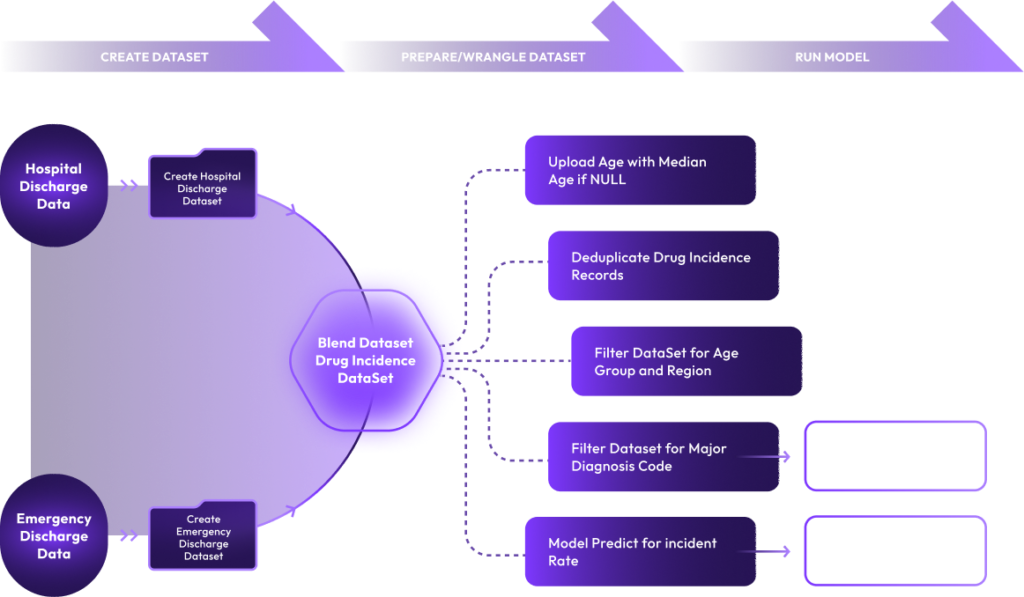
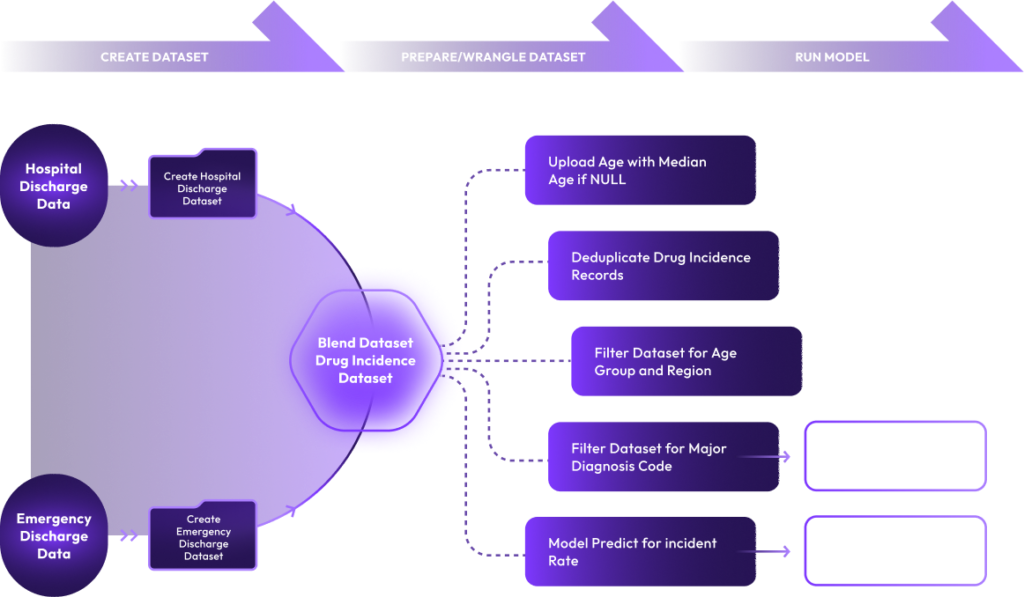
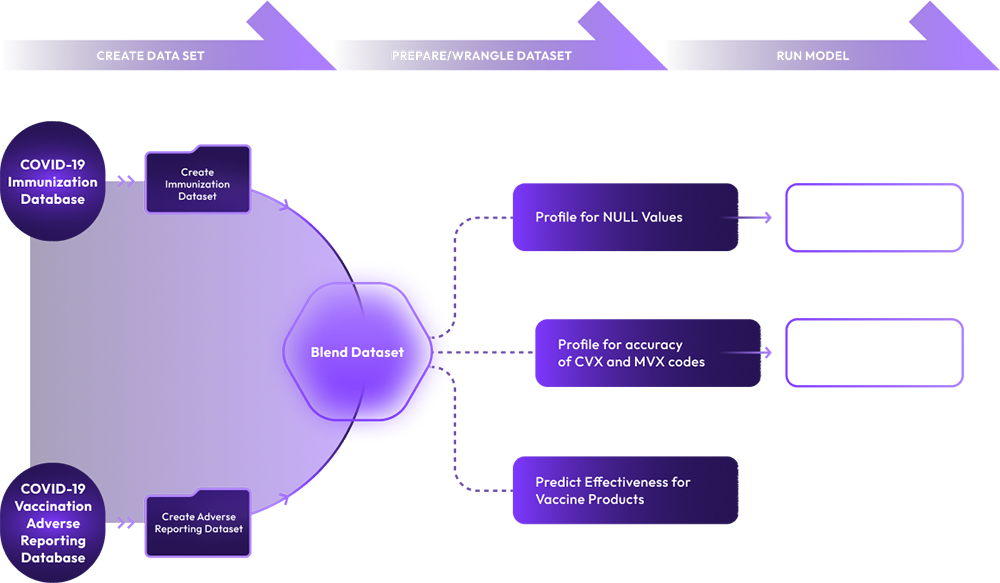
xAQUA UDP allows you to perform various Data Wrangling tasks on a dataset such as merging, grouping, deduplicating, aggregating, filtering, text processing, translating, and concatenating, etc. for various purposes as follows.
Prepare Dataset to train your ML Models
Prepare Datasets to feed ML and Predictive Models
Prepare Datasets to load to a Data Warehouse
Perform Exploratory Data Analysis
Prepare Datasets for Analytics and Visualization
Data Profiling is a critical step in data preparation often primarily in context to a specific business analytics use case. The profiling of a dataset is used to ensure the accuracy, completeness, and integrity of data in a dataset in context to an analytics use case.
With xAQUA UDP you can create low-code/no-code data pipeline to perform various types of data profiling on Datasets.
Structure and Pattern Profiling: Profile Datasets to ensure the values in columns of a Dataset conforms to certain structural patterns. Examples include, Date, Zip Code, SSN, ICD, SNOMED codes etc.
Value/Content Profiling: Profile Dataset to check for Nulls, range of values, value list, low and high values etc.
Integrity/Reference Profiling: Integrity profiling may involve more than one Dataset/Tables and checks for referential integrity of the data as follows.
Detect Identifying Key: Profile a Dataset to identify one or more columns that are potential identifying/key columns.
Detect Foreign keys: Profile multiple Datasets/Tables to identify a column as a foreign key column
xAQUA® Composer allows you to compose data pipelines for Apache Airflow using a low-code/no-code drag-and-drop workflow editor as a Directed Acyclic Graph (DAG). The Python script for the DAG is automatically generated and can be deployed to an environment with just a few clicks.