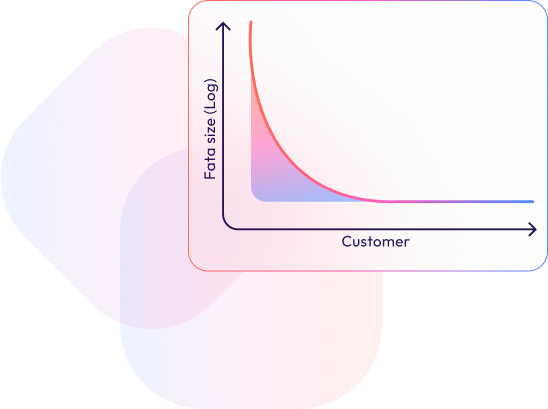
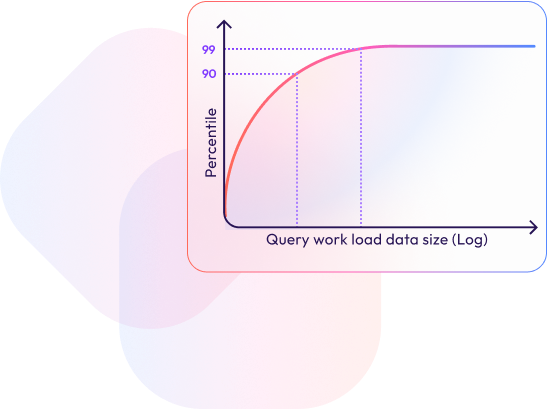
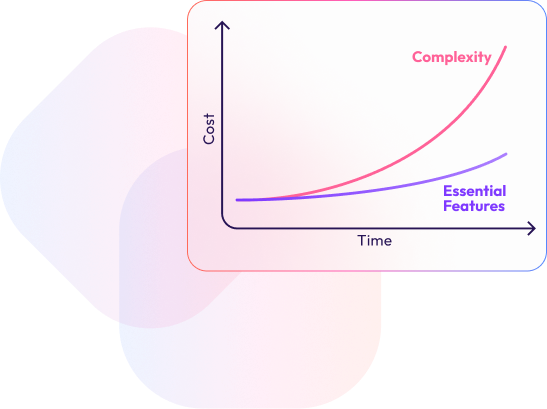
As the concept of Big Data continues to evolve, it is becoming clear that the true value lies not in the sheer volume of data but in the ability to manage, analyze, and derive insights from that data efficiently. xAQUA Analytics Data Lake represents the future of data management, offering a solution that is both nimble and powerful, without the unnecessary complexity and cost of traditional Big Data infrastructures.