
Apache Kafka is ideal for real-time data streaming where users require data retention per its timelines. While with AWS Kinesis, the data evaporates once the consumer has read it.
Apache Kafka offers the flexibility to manually configure and tune the performance as per the user’s requirements which is not seen with AWS Kinesis. However, the latter is much more cost-efficient, offering AWS-based infrastructural costs and lower engineering costs.
The battle between the two is real. A study at Confluent established that Kafka could handle over 1 million messages per second at 10 milliseconds of latency, whereas Kinesis can only handle 120,000 messages per second at 150 milliseconds of latency. Kafka outranks Kinesis, with 86% of respondents in a survey conducted by Confluent voting for Kafka as their primary choice for real-time streaming solutions.
Kafka and Kinesis are close contenders offering their perks that one must be aware of. Kafka is ideal for dynamic data processing requirements with its easy integration capabilities and seamless scalability over a self-hosted or cloud platform. In contrast, Kinesis(offered by AWS) is an ideal solution for cloud-based real-time data streaming services for organizations already working with AWS. It requires a fully managed, automatically scalable, and pay-as-you-go pricing structure.

Source – Reddit
Either alternative is a strong contender, and it all comes down to your requirements, budget, and business needs. However, building your own data stack is challenging, time-consuming, and an expensive journey.
In this post, we shall not only compare Apache Kafka and AWS Kinesis but also introduce an all-in-one solution for businesses looking to monetize their enterprise data assets without a significant investment of resources.
Be it the open-source flexibility of Apache Kafka or fully managed ease of use with AWS Kinesis, both platforms are robust, scalable, fault-tolerant, and reliable solutions with efficient data processing capabilities.

Let’s dive deep into why users love these tools and what’s the catch to ease your selection per your unique business requirements.
Certainly Cost-Effective: As Kafka is open source, it’s free to use basic Kafka. While for managed Kafka service offered by a cloud provider, users need to pay for it. Pricing depends on the number of nodes, the amount of data processed, and the data retention period.
Effectively Handles the Critical Data: Kafka’s design and architecture provide users with a distributed, partitioned, and replicated system. This means that data can be duplicated across different nodes, ensuring high availability, low latency, and fault tolerance.
For businesses operating in industries like e-commerce, critical data such as website traffic, user buying behavior, and recommendation engines can be easily replicated across various servers using Kafka. This provides high availability of the data, real-time processing for faster decision-making, quick response times, and high scalability when website traffic spikes. Overall, Kafka offers an efficient solution for handling massive volumes of crucial data.
Offers Flexibility And Adaptability: Businesses could customize and adapt Kafka per their needs. Kafka’s open-source nature offers access and ease of modification to the source code; the business could tailor Kafka to suit their specific use cases, workloads, and environments. They could also choose from an extensive range of tools, integrations, and extensions developed by the community.
Offers Versatility And Usability: You can process large volumes of data in real-time, enabling you to make data-driven decisions quickly and efficiently. In addition, data from various sources could be rapidly processed with Kafka. Kafka’s versatility to integrate multiple data sources offers a scalable architecture. Hence, its simplicity, ease of understanding documentation, and community support make it an easy-to-use platform.
While the talks about Kafka are positive, we cannot miss the shadowed areas behind the brilliance. For some businesses, there might be better solutions than Kafka suiting their needs.
So let us explore where Kafka could have done better.

Source – Reddit

Source – Reddit
Although Kafka is an open-source and free-to-distribute streaming platform, some costs couldn’t be overlooked. As a result, you shall be charged as per your usage (including infrastructure, storage, and data transfer costs) if you are willing to onboard Kafka on a cloud platform like AWS.
Besides this, integrating Kafka with third-party tools comes at a cost. Be it the licensing, hardware, or cloud-hosting costs. You will have to separately purchase additional tools for data processing, monitoring, and management, while Kafka already takes care of the core messaging and streaming capabilities.
Suppose you are building projects with more detailed requirements for a big project; integrating Kafka is a good decision. On the other hand, working with Kafka for smaller developments might push you to take unnecessary complexity, such as setting up and managing the clusters. Moreover, small projects have limited budgets. Hence simpler streaming systems are a better option to go for.
Some limitations are also seen with availability. Kafka offers high availability if adequately planned, configured and managed only. However, this poses a lot of stress on the team who is implementing Kafka. Groups working with Kafka need to invest a significant amount of time. For setting the replication of Kafka across various servers to ensure continuity of data is maintained when one server goes down, the healthy server picks up from there. Teams have to plan for disaster recoveries and configure the settings themselves carefully. In addition, businesses need to hire people with technical expertise to integrate Kafka, which adds up the cost.
Low Latency, Data Inconsistency:
With Kafka, users may experience delays in processing and potential inconsistencies in the data when the architecture is so designed that vast columns of data are replicated over various nodes.
Source – Reddit
Apache Kafka has challenges in elasticity, scalability, reliability, and flexibility. For instance, when website traffic spikes, adding Kafka brokers to support the capacity can add complexity. Over-optimizing configurations can lead to more time tweaking systems instead of delivering value to customers. As systems, data, infrastructure, and technology evolve, time is wasted managing complex configurations. Modifying configurations can increase the risk of data loss, errors, and downtime, affecting the system’s flexibility and reliability.
Moving towards the cloud, AWS Kinesis seamlessly overcomes the challenges Kafka poses. Its fully-managed solution simplifies the transition process, eliminating the need to deal with Kafka’s complexities. In addition, Kinesis caters to the digital transformation age by offering built-in integrations with other AWS services, making it more convenient for users. It also provides automatic scalability for real-time streaming data and greater flexibility in customizing the retention period of data streams. This approach offers excellent flexibility with minimal risk of disrupting established processes.
Let’s understand how AWS Kinesis contrasts with Apache Kafka.

Source – Reddit
Seamless Scalability:
AWS Kinesis provides a smooth experience for processing real-time streaming data that can automatically scale with increasing data volume. Its users highly appreciate Kinesis’s ability to keep up with the increasing data without requiring significant modifications such as additional configurations, demanding architectural changes, or infrastructure changes.
Maintaining the flow of streaming real-time data is crucial, and AWS Kinesis does just that without slowing down or causing downtime. It seamlessly adapts to changing demands, so users only pay for what they use without incurring additional infrastructure or architectural costs.
Convenient Customization:
Customizing data streams to meet business needs is made easy with AWS Kinesis. It requires some planning effort from the team to determine the number of shards needed to handle the data processing rate and the retention period to prevent data loss. However, users can take advantage of the additional custom data processing logic offered by AWS Kinesis by using AWS Lambda functions or third-party tools.
AWS Kinesis is flexible enough to work consistently with various data sources. This allows users to unrestrictedly approach solutions suiting their requirements rather than streamlining the solution of a platform’s offer. In addition, this enables users to perform custom data processing and analysis on their data as it’s being streamed, providing them with real-time insights to make informed business decisions.
Highly Available Yet Reliable:
AWS Kinesis offers automatic high availability, making it more reliable than Apache Kafka. In addition, with the ability to replicate data across multiple availability zones, Kinesis assures its users that their data is safe even during times of failure. This provides businesses with peace of mind and the ability to focus on making data-driven decisions, knowing that their data is preserved and duplicated with Kinesis.
AWS Kinesis leverages elastic scaling to provide high availability during peak traffic periods and low availability during off-peak periods, ensuring that your business can handle varying traffic levels seamlessly.
Choosing between Apache Kafka vs. AWS Kinesis depends entirely on your business needs and requirements, budget, engineering cultures, and organization’s capabilities. While Apache Kafka outranks AWS Kinesis with its more flexible and customizable solutions, Kinesis proves to be a superior alternative regarding requirements for fully managed, automatically scalable options.
You might be transitioning to the cloud and find Kinesis a better real-time streaming cloud-native option. Even though Kafka can be deployed on the cloud, monitoring, managing, and maintaining servers and security would still create some manual IT overhead. But once the decision is made, you can easily and quickly start working with the real-time streaming data to make the data-informed decision.
But does this call for creating the entire data stack on your own?
Once your real-time streaming data sits in Kafka or Kinesis, you will begin exploring other tools and technologies to complete your data stack. While it is certainly feasible to build a new data stack from scratch, it’s essential to consider the significant investment of time, resources, and expertise that such an undertaking would require.
Presenting, xAqua – Unified Data Platform. xAQUA® UDP is a unified data platform that simplifies enterprise data and analytics challenges via its high-quality, all-in-one, self-service tools and technologies for effective data management, analytics, and collaboration. In addition, the xAQUA® UDP platform handles common obstacles related to time, cost, quality, trust, and risk smoothly via its data quality-first approach.
Users can embark on their data analytics journey with crystal-clear visibility and deep observability tools. Users can walk into data-driven insights in one place, from data preparation to analysis.
The traditional “Tool Centric Output-focused” approach can lead to chaos. Building a data stack from scratch is complex and requires significant time, effort, and money. In addition, challenges like finding multiple tools, complex processes, fragmented solutions, and heavy reliance on Subject Matter Experts (SMEs) for their domain knowledge can delay the delivery of integrated, clean, curated, and trusted data. This is particularly challenging for smaller organizations with limited budgets that may need access to the skilled resources and technical expertise required to deliver trusted data on time.
Businesses may strain their resources to pursue faster targets, resulting in higher costs and delays in delivering integrated, reliable, and trusted datasets. For data-driven companies, maintaining high data quality is critical. Still, the sheer volume of data can make it challenging to manage, monitor, and maintain accuracy, leading to inaccuracies and inconsistencies. Finally, generating real-time data insights from massive data sets can take time, especially for businesses with the proper tools, processes, and technologies.
xAqua® UDP offers a solution-centric approach focused on outcomes rather than outputs. It’s an all-in-one, integrated, and automated platform for Enterprise Data Operations that delivers capabilities for data operations, analytics, management, and governance out of the box. Unlike a DIY data stack, xAqua is easy to use and deploy, requiring no technical expertise.
xAqua® UDP focuses on outcomes to help customers drive efficient monetization. It delivers reliability and gains trust with certified Live Data as a Product (LDaaP) for data consumers. xAqua reduces technology dependencies, hidden costs, time, and risks by empowering the team with self-service data operations. Users can prepare data and run analytics through an interactive user interface and low code/no code solutions, making it easy for everyone on the team.
Built with scalability in mind, xAQUA® UDP ensures businesses can easily manage, monitor and maintain the data pipelines dealing with vast volumes of data.
xAQUA® UDP is a unified data platform that simplifies enterprise data and analytics challenges via its high-quality, all-in-one, self-service tools and technologies for effective data management, analytics, and collaboration. In addition, the xAQUA® UDP platform handles common obstacles related to time, cost, quality, trust, and risk smoothly via its Data Quality-First Approach.
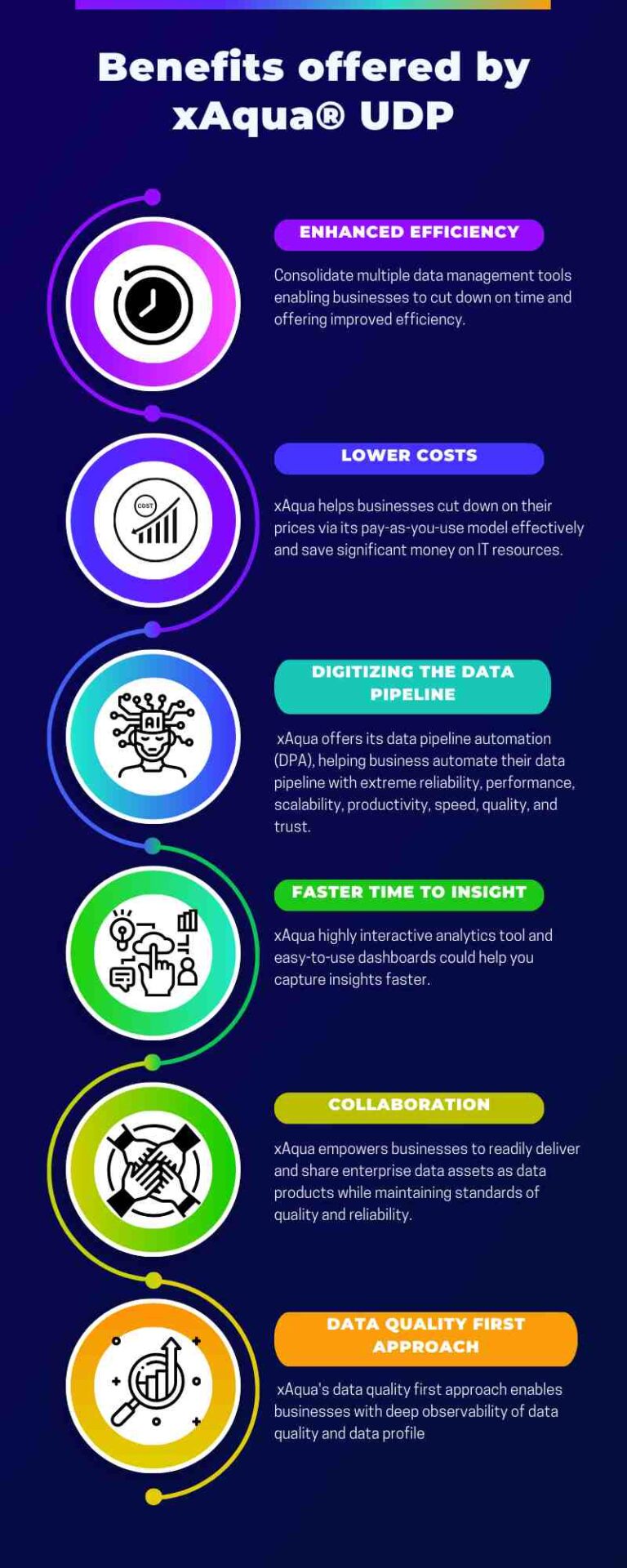
#1. Enhanced Efficiency: Consolidate multiple data management tools into a unified data platform enabling businesses to cut down on time and improve efficiency.
#2. Developed Data Quality: xAqua offers built-in data quality controls and validation tools, ensuring high data accuracy and consistency, thereby minimizing the chance of mistakes and imprecisions.
#3. Supreme Scalability: With xAqua’s supreme scalability, businesses can efficiently manage, monitor and maintain huge volumes of data without worrying about resource constraints.
#4. Data Quality First Approach: Powered to deliver accurate and actionable analytics with a certificate of trust, xAqua’s data quality first approach enables businesses with deep observability of data quality and data profile at each step of their data analytics journey.
#5. Lower Costs: xAqua has significantly lowered costs by combining various data management tools into a unified data platform. This helps businesses cut their prices, allows smaller organizations or smaller projects to use its pay-as-you-use model effectively, and saves significant money on IT resources.
#6. Digitizing The Data Pipeline: To address the ever-growing complex data pipeline requirements, xAqua offers its data pipeline automation (DPA) which helps businesses automate their data pipeline with extreme reliability, performance, scalability, productivity, speed, quality, and trust.
#7. Deliver And Collaborate On The Data Assets As Data Products: xAqua empowers businesses to readily deliver and share enterprise data assets as data products while maintaining standards of quality and reliability.
#8. Faster Time To Insight: xAqua ensures the business can invest more time in data-driven decisions. Hence, its highly interactive analytics tool and easy-to-use dashboards could help you capture insights faster.
Overall, xAqua UDP can integrate well with any data warehouse system, offering a flexible, reliable, and adaptable solution for businesses of all sizes and industries. Experience the flexible xAQUA® platform igniting efficiency and streamlining business data management processes.
Deciding between Apache Kafka vs. AWS Kinesis depends entirely on your business needs, requirements, monetary budgets, and organization infrastructure. Both real-time streaming solutions have their own set of pros and cons.
But once your decision is made, you can quickly start generating analytics from the data coming from either Apache Kafka or AWS Kinesis using xAqua. xAQUA® UDP is a unified data platform that simplifies enterprise data and analytics challenges via its high-quality, all-in-one, self-service tools and technologies for effective data management, analytics, and collaboration.
Book an in-person demo with team xAqua today! Our experts will walk you through the entire platform and show how it can help you monetize your data from day one.